Inception
Going Deeper With Convolutions was the 2014 paper that introduced the "Inception" architecture, which consisted of stacking "modules" to form a deep neural network. "GoogLeNet", the winner of the ImageNet Large Scale Visual Recognition Competition (ILSVRC) in 2014 was one such network.
The goal was to make deeper, wider networks without increasing computational resources. Before this paper, networks were typically simply stacked convolutions with some pooling, dropout, and normalization layers mixed in.
This paper notes that, while sparse networks have desirable theoretical properties, they're almost never used due to the fact that dense matrix multiplication is so efficient — even if only 1% of a sparse matrix is non-zero, the dense operation is often faster.
There is also the "Hebbian principle" — "neurons that fire together, wire together", which suggests that sparse matrices want to connect highly correlated neurons.
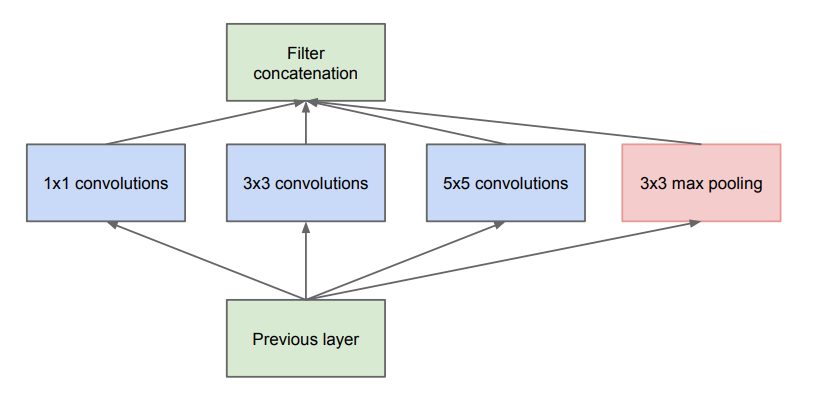
Convolutions offer precisely this kind of sparse connections (since neighboring neurons are often highly correlated), but with the performance of dense operations. But if we justify convolutions using the Hebbian principle, one would expect that wide filters are of limited use, since neurons that are 5 pixels away from each other are far less likely to be correlated than neurons that are 3 pixels away.
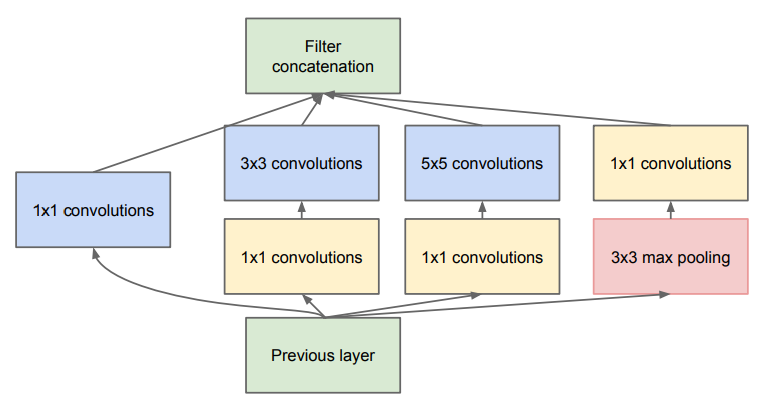
With these heuristics in mind, the authors suggest a module that has a few 5x5 filters and far more 3x3 and 1x1 filters. They also, for good measure, suggest adding a max pooling layer (with stride=1), since max pooling has proven so valuable in the past.
To help keep model size small, they throw in some 1x1 convolutions to reduce the number of channels before the expensive 3x3 and 5x5 convolutions.
Finally, they find that inserting an intermediary shallow classifier in the middle of the network and propagating loss from it (in addition to the head at the end of the network) with a weight of 0.3 helps combat the vanishing gradient problem and gives them minor accuracy gains.